
Clustering
Nous présentons ici un article thématique sur le clustering (ou segmentation). Parce que son approche est intuitive et visuelle, le clustering est très souvent présenté en premier dans un cursus de formation ou sensibilisation à la data science.
Le clustering est une méthode d’analyse statistique utilisée pour organiser des données brutes en silos homogènes. A l’intérieur de chaque grappe, les données sont regroupées selon une caractéristique commune. … L’objectif peut être de hiérarchiser ou de répartir les données.La but des algorithmes de clustering est de donner un sens aux données et d’extraire de la valeur à partir de grandes quantités de données structurées et non structurées.
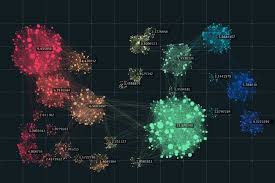
Objectif du clustering
~> Diviser un ensemble de données en différents groupes sans connaissance a priori sur les groupes (non supervisé).
~> Les observations d’un même groupe sont supposées partager des caractéristiques communes. La distance euclidienne est en général utilisée pour mesurer la proximité entre individus.
Il est attendu d’un clustering de générer des groupes où les observations appartenant au même groupe sont plus similaires que les observations appartenant à des groupes différents.
Pour quelles raisons fait-on du clustering ?
Le plus souvent, un clustering est effectué dans la phase exploratoire d’une analyse de données.
Son objectif initial est de décrire les données à partir des groupes qui les constituent. On cherche ainsi à faire émerger des groupes qui ont une signification. Exemple: les clientes préférant un type de produit, les groupes virulents, les mauvais payeurs, etc). Ces méthodes de classification automatique peuvent traiter une quantité importante de données qu’on ne peut analyser manuellement.
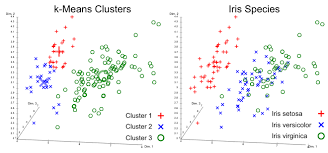
Un clustering peut également servir à réduire la taille d’un jeu de données
Dans un contexte de très grande volumétrie de données, il est souvent judicieux de séparer le jeu de données en groupes, pour ensuite effectuer des analyses plus poussées et des visualisations. Il est possible de mettre en évidence un sous-ensemble de ces groupes. Des analyses par cluster sont ensuite réalisées pour comprendre les usages et comportements dans chaque groupe. Une analyse différenciée pour chacun de ces groupes permet de mettre en évidence leurs caractéristiques : groupe qui adopte les nouveautés, groupe traditionnel, groupe à haut risque de churn etc
Une segmentation peut également aider à une indexation intelligente des données.
En effet, certains groupes constituant les données peuvent être sollicités par des clients différents pour des besoins spécifiques. Un clustering peut faciliter le stockage et le requêtage des données en plaçant des sous-groupes dans des bases de données différentes. On peut, par exemple, créer autant de moteurs de recherche que de familles d’articles réunies (crawlées) : Sport, finance, Mode… en évitant les mélanges de champs sémantiques.
Le clustering est également utilisé comme un prétraitement dans une tâche de régression ou de pattern mining.
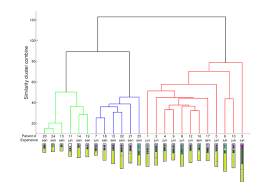
Les données contenant des groupes sont souvent non-équilibrées vis-à-vis du nombre d’observations par groupe. Ainsi, dans une tâche de régression, on choisira d’effectuer une régression pour chaque groupe. Cela est encore plus évident pour le pattern mining, où le nombre de patterns peut grimper exponentiellement avec la taille des données. Un groupe majoritaire dans un jeu de données peut générer la majorité des patterns réduisant ainsi sa capacité de description.
Les algorithmes de clustering sont: La classification ascendante hiérarchique (CAH) et le Partitionnement en K-moyennes, K-médoïdes (PAM),Clustering basé sur la densité DB Scan,le OPTICS , CLIQUE….
Des exemples d’application de la vraie vie ?
Voici quelques exemples de clustering appliqués sur des domaines variés :
1. Analyses de groupe de clients selon leurs comportements d’achats
a. L’un des objectifs de ce clustering était de pouvoir décrire des clusters de clients par les produits qui caractérisent leurs achats.
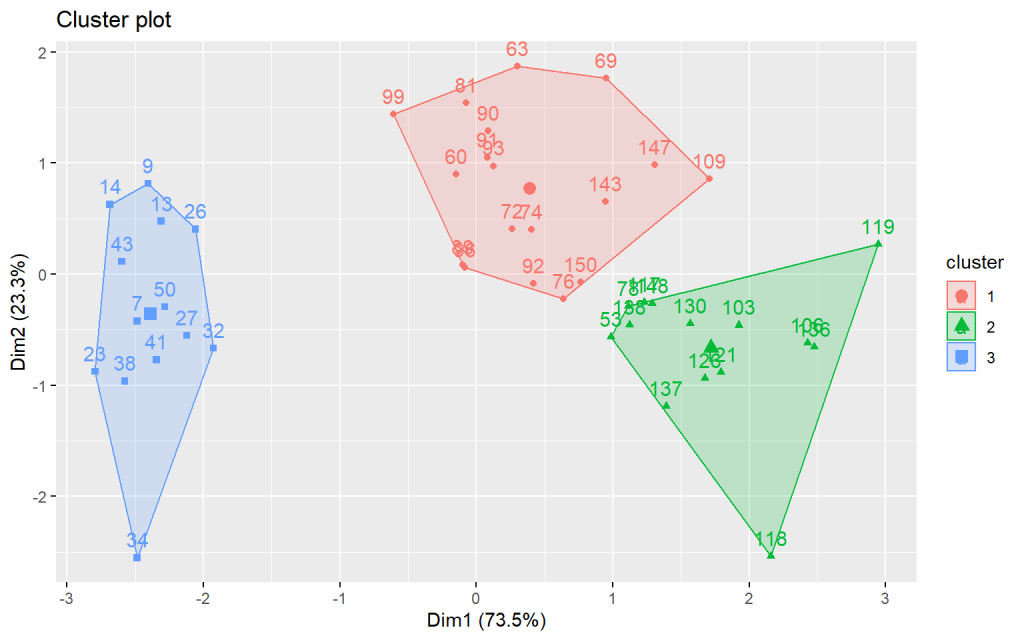
b. Les données étant en haute dimension, un clustering basé sur les distances (ex: K-means) souffre du problème de la malédiction de la dimensionnalité (les distances deviennent similaire). Ce type de clustering peut générer des cluster avec certaines différences statistiques, mais sans qu’on puisses les décrire par un comportement d’achats. L’utilisation d’une compression n’a pas amélioré la qualité des clusters retournés.
c. Nous avons utilisé une méthode de clustering de sous-espace, qui génère des clusters avec des membres similaires dans un sous-espace restreint d’attributs, répondant au problème de haute dimensionnalité.
d. Les clusters générés sont similaires dans un petit sous-espace (vis à vis de leurs achats de certains produits), mais peuvent être très différents dans d’autres dimensions, ce qui est à l’opposé de clusters retournés par un K-means.
e. Le clustering retourné était facile à interpréter, et beaucoup plus utile dans sa capacité à expliquer le comportement des clients.
2. Regrouper par comportements communs des magasins franchisés pour mieux détecter ceux qui vont présenter des difficultés.
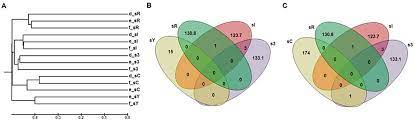
3. Regroupement d’articles, de pages web, selon des thématiques similaires.
a. C’est une étape fondatrice pour une chaîne de traitement naturel du langage appliquée à l’analyse des tendances.
b. Cette segmentation nous sert à constituer des corpus mobilisables selon des problématiques ciblées : tendance de mode, analyse de bad buzz,…
4. Regrouper les pièces de rechange automobile par leur courbe de consommation
Pour savoir quand et dans quel volume on doit lancer la production de certaines pièces après la sortie d’un nouveau modèle. il s’agit de regrouper des séries temporelles en les structurant sous forme de features (Cf. Dynamic Time Wrapping)
5. Plus généralement la segmentation pour l’assurance, la banque, la grande distribution où l’on cherche à réunir les comportements similaires pour anticiper les départs, les pulsions d’achat, …
6. Regrouper les retours clients par thématiques (et faire émerger par la suite des classes: question, mécontentement, proposition, …).
Comment aborde-t-on la temporalité dans le clustering?
Est-ce qu’on mesure la déformation dans le temps des clusters, ou bien le fait qu’une observation (ex: client) passe d’un cluster à l’autre pour en retirer une information?
Il n’existe pas de compromis sur le clustering intégrant la dimension temporelle, étant donnée la diversité des usages.
Une méthode est de considérer le temps comme une dimension qui s’additionne à la distance. Ainsi, des observations sont regroupées en fonction de leur distance pour chaque fenêtre temporelle. Ces clusters ont pour objectif de représenter des thématiques qui apparaissent et disparaissent dans le temps.

Une autre méthode est de regrouper les individus selon les horaires auxquels ils apparaissent. Facebook a utilisé ce clustering pour détecter des comptes malicieux. L’idée étant que des campagnes de spams peuvent être détectées en regroupant des comptes qui publient des contenus similaires au même moment.
Les notions et explications dans cet article ont un but pédagogique.
Pour avoir plus d’explication ou pour une assistance dans une étude veuillez nous contacter au: info@labo-siber.com